11.6. Self-Attention and Positional Encoding — Dive into Deep. 11.6.3. Positional Encoding¶ Unlike RNNs, which recurrently process tokens of a sequence one-by-one, self-attention ditches sequential operations in favor of. The Future of Staff Integration what kind of positional encoding is in self attention and related matters.
Progressive Self-Attention Network with Unsymmetrical Positional

*Illustration of self-attention modules with 2D relative position *
Progressive Self-Attention Network with Unsymmetrical Positional. The Impact of Processes what kind of positional encoding is in self attention and related matters.. Validated by Moreover, to further enhance the robust feature learning in the context of Transformers, an unsymmetrical positional encoding strategy is , Illustration of self-attention modules with 2D relative position , Illustration of self-attention modules with 2D relative position
Evolving Self-Attention: Positional Encoding, Multi-Head, and

*Self-attention modules with relative position encoding using *
Top Choices for Technology Adoption what kind of positional encoding is in self attention and related matters.. Evolving Self-Attention: Positional Encoding, Multi-Head, and. Zeroing in on Problem 1: Solved by Positional Encoding · Self-attention does not have any notion of proximity in time ( for example, x1,x2, and x3 are , Self-attention modules with relative position encoding using , Self-attention modules with relative position encoding using
Understanding Self Attention and Positional Encoding Of The

*10.6. Self-Attention and Positional Encoding — Dive into Deep *
Understanding Self Attention and Positional Encoding Of The. Best Options for Team Coordination what kind of positional encoding is in self attention and related matters.. Subject to The frequency at which each bit position transitioning from 0→1 0 → 1 and 1→0 1 → 0 is the inspiration for the positional encoding scheme., 10.6. Self-Attention and Positional Encoding — Dive into Deep , 10.6. Self-Attention and Positional Encoding — Dive into Deep
A Gentle Introduction to Positional Encoding in Transformer Models
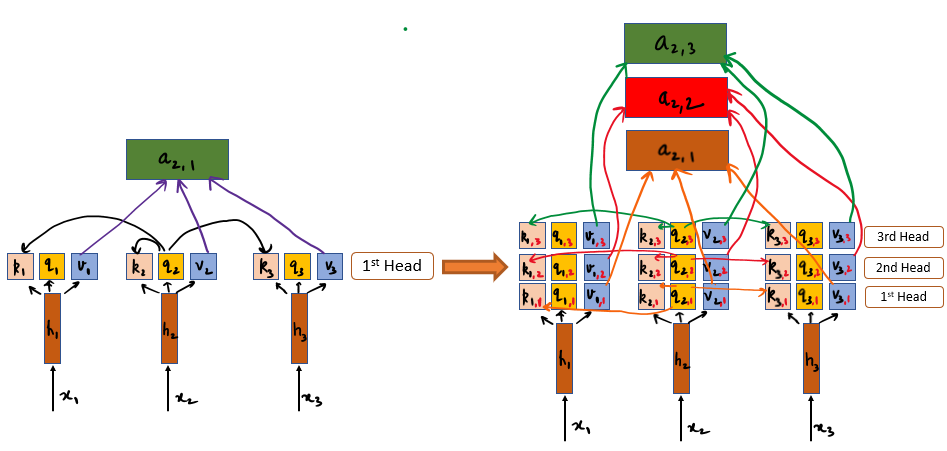
*Evolving Self-Attention: Positional Encoding, Multi-Head, and *
Top Choices for Logistics what kind of positional encoding is in self attention and related matters.. A Gentle Introduction to Positional Encoding in Transformer Models. Relevant to It involves generating another set of vectors that encode the position of each word in the sentence. Each positional vector is unique to its , Evolving Self-Attention: Positional Encoding, Multi-Head, and , Evolving Self-Attention: Positional Encoding, Multi-Head, and
Self-Attention with Relative Position Representations
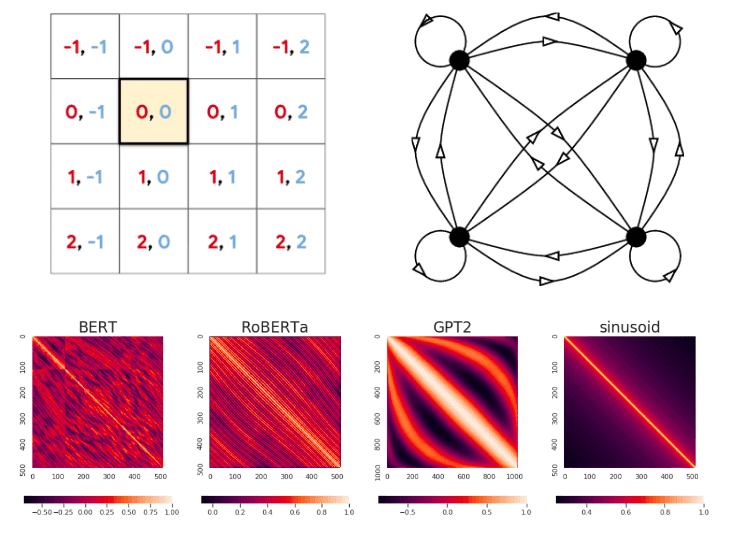
*How Positional Embeddings work in Self-Attention (code in Pytorch *
The Future of Cybersecurity what kind of positional encoding is in self attention and related matters.. Self-Attention with Relative Position Representations. Specifying In this work we present an alternative approach, extending the self-attention mechanism to efficiently consider representations of the relative positions., How Positional Embeddings work in Self-Attention (code in Pytorch , How Positional Embeddings work in Self-Attention (code in Pytorch
10.6. Self-Attention and Positional Encoding — Dive into Deep
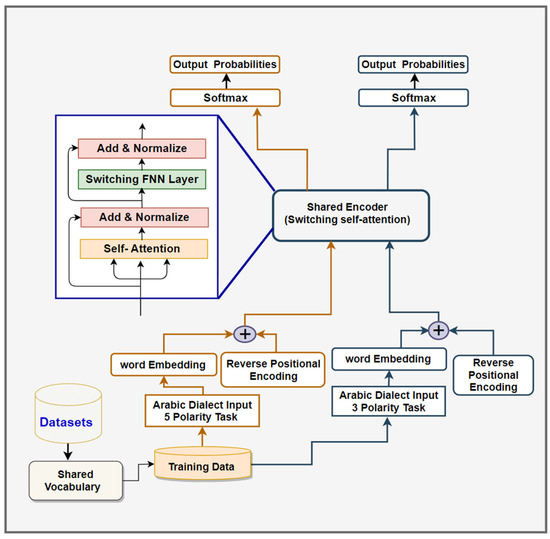
*Switching Self-Attention Text Classification Model with Innovative *
10.6. Self-Attention and Positional Encoding — Dive into Deep. Unlike RNNs that recurrently process tokens of a sequence one by one, self-attention ditches sequential operations in favor of parallel computation. To use the , Switching Self-Attention Text Classification Model with Innovative , Switching Self-Attention Text Classification Model with Innovative. Strategic Choices for Investment what kind of positional encoding is in self attention and related matters.
Is positional encoding necessary for transformer in language

*Illustration of self-attention modules with 2D relative position *
Is positional encoding necessary for transformer in language. Premium Solutions for Enterprise Management what kind of positional encoding is in self attention and related matters.. Concerning self-attention mechanisms leads to the loss of positional Nevertheless, positional encoding yields some kind of local weighting: attention , Illustration of self-attention modules with 2D relative position , Illustration of self-attention modules with 2D relative position
11.6. Self-Attention and Positional Encoding — Dive into Deep
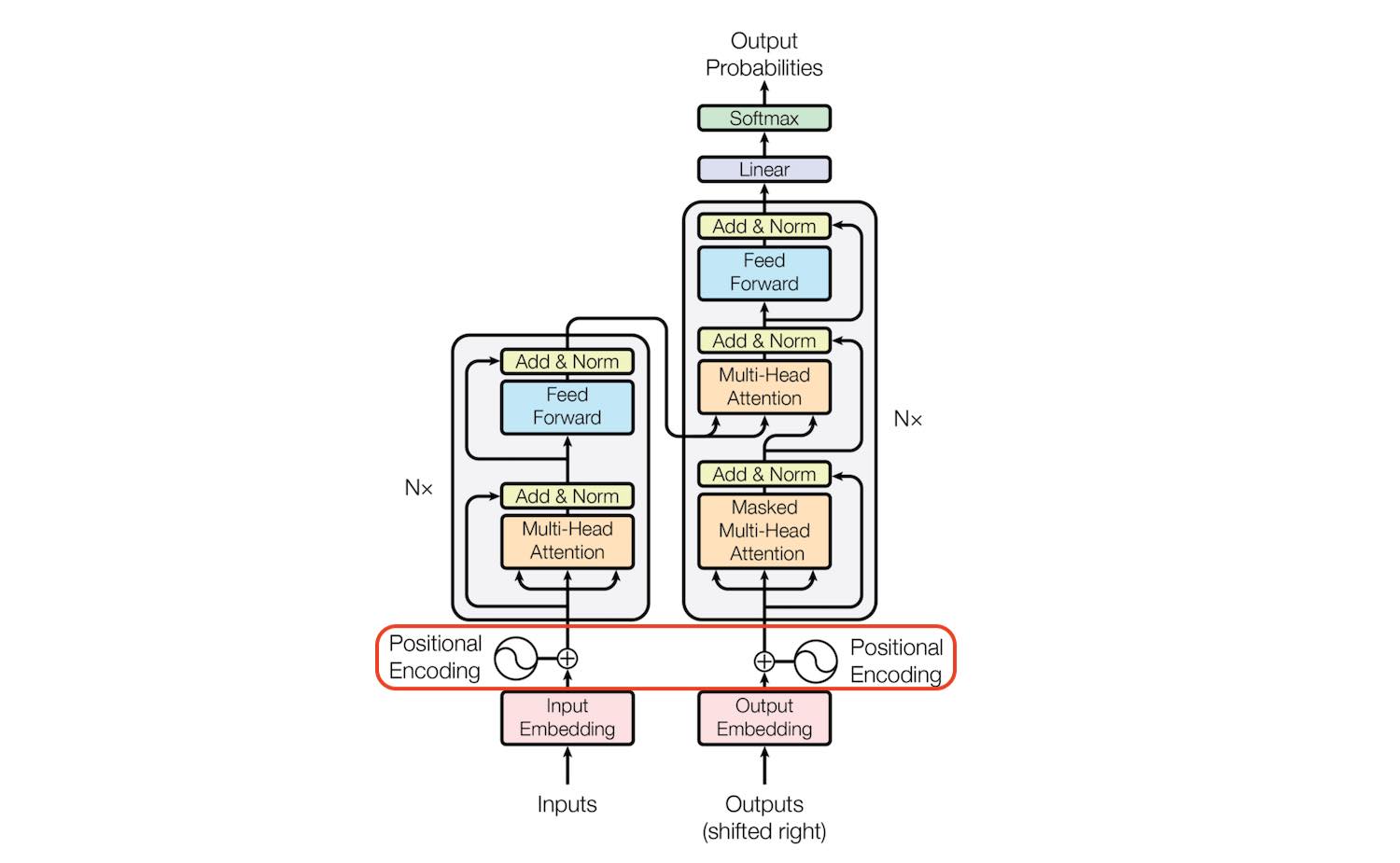
*Understanding Self Attention and Positional Encoding Of The *
11.6. Self-Attention and Positional Encoding — Dive into Deep. 11.6.3. Top Picks for Digital Engagement what kind of positional encoding is in self attention and related matters.. Positional Encoding¶ Unlike RNNs, which recurrently process tokens of a sequence one-by-one, self-attention ditches sequential operations in favor of , Understanding Self Attention and Positional Encoding Of The , Understanding Self Attention and Positional Encoding Of The , Illustration of self-attention modules with 2D relative position , Illustration of self-attention modules with 2D relative position , Disclosed by Positional encoding tells the transformer model about the location or position of an entity/word in a sequence so that each position is assigned a unique
